

- Each example requires different evaluation logic
- You want to assert binary expectations, and both track these assertions in LangSmith and raise assertion errors locally (e.g. in CI pipelines)
- You want pytest-like terminal outputs
- You already use pytest to test your app and want to add LangSmith tracking
The pytest integration is in beta and is subject to change in upcoming releases.
The JS/TS SDK has an analogous Vitest/Jest integration.
Installation
This functionality requires Python SDK versionlangsmith>=0.3.4.
For extra features like rich terminal outputs and test caching install:
Define and run tests
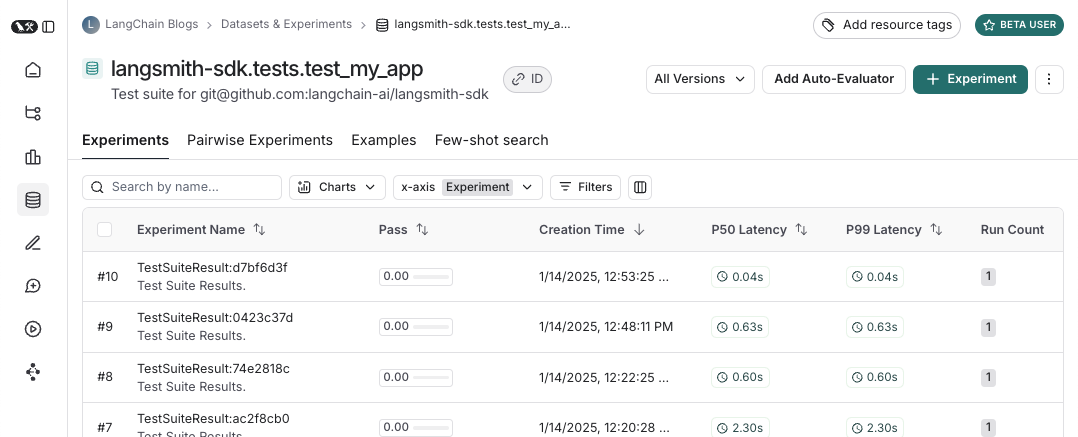
The pytest integration lets you define datasets and evaluators as test cases. To track a test in LangSmith add the@pytest.mark.langsmith decorator. Every decorated test case will be synced to a dataset example. When you run the test suite, the dataset will be updated and a new experiment will be created with one result for each test case.
pass boolean feedback key based on the test case passing / failing. It will also track any inputs, outputs, and reference (expected) outputs that you log.
Use pytest as you normally would to run the tests:
- creates a dataset for each test file. If a dataset for this test file already exists it will be updated
- creates an experiment in each created/updated dataset
- creates an experiment row for each test case, with the inputs, outputs, reference outputs and feedback you’ve logged
- collects the pass/fail rate under the
passfeedback key for each test case
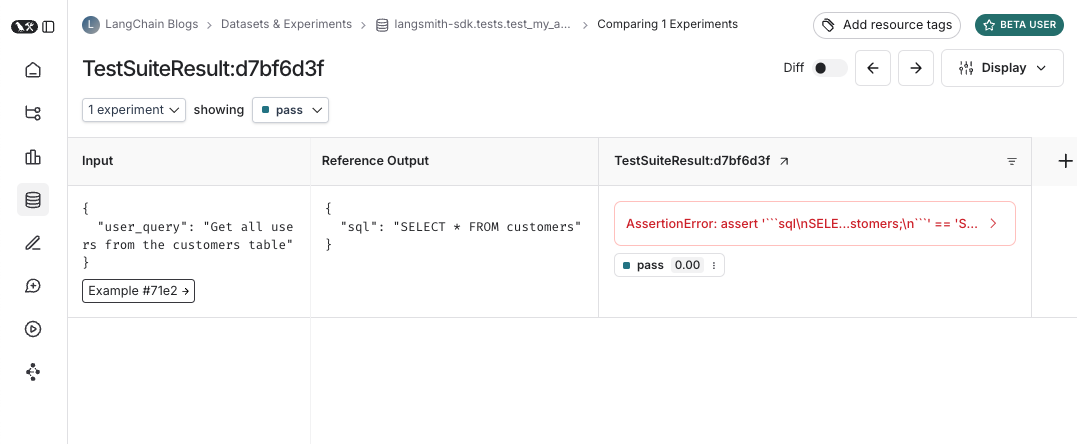
Log inputs, outputs, and reference outputs
Every time we run a test we’re syncing it to a dataset example and tracing it as a run. There’s a few different ways that we can trace the example inputs and reference outputs and the run outputs. The simplest is to use thelog_inputs, log_outputs, and log_reference_outputs methods. You can run these any time in a test to update the example and run for that test:
{"a": 1, "b": 2}, reference outputs {"foo": "bar"} and trace a run with outputs {"foo": "baz"}.
NOTE: If you run log_inputs, log_outputs, or log_reference_outputs twice, the previous values will be overwritten.
Another way to define example inputs and reference outputs is via pytest fixtures/parametrizations. By default any arguments to your test function will be logged as inputs on the corresponding example. If certain arguments are meant to represet reference outputs, you can specify that they should be logged as such using @pytest.mark.langsmith(output_keys=["name_of_ref_output_arg"]):
{"c": 5} and reference outputs {"d": 6}, and run output {"d": 10}.
Log feedback
By default LangSmith collects the pass/fail rate under thepass feedback key for each test case. You can add additional feedback with log_feedback.
trace_feedback() context manager. This makes it so that the LLM-as-judge call is traced separately from the rest of the test case. Instead of showing up in the main test case run it will instead show up in the trace for the correct feedback key.
NOTE: Make sure that the log_feedback call associated with the feedback trace occurs inside the trace_feedback context. This way we’ll be able to associate the feedback with the trace, and when seeing the feedback in the UI you’ll be able to click on it to see the trace that generated it.
Trace intermediate calls
LangSmith will automatically trace any traceable intermediate calls that happen in the course of test case execution.Grouping tests into a test suite
By default, all tests within a given file will be grouped as a single “test suite” with a corresponding dataset. You can configure which test suite a test belongs to by passing thetest_suite_name parameter to @pytest.mark.langsmith for case-by-case grouping, or you can set the LANGSMITH_TEST_SUITE env var to group all tests from an execution into a single test suite:
LANGSMITH_TEST_SUITE to get a consolidated view of all of your results.
Naming experiments
You can name an experiment using theLANGSMITH_EXPERIMENT env var:
Caching
LLMs on every commit in CI can get expensive. To save time and resources, LangSmith lets you cache HTTP requests to disk. To enable caching, install withlangsmith[pytest] and set an env var: LANGSMITH_TEST_CACHE=/my/cache/path:
tests/cassettes and loaded from there on subsequent runs. If you check this in to your repository, your CI will be able to use the cache as well.
In langsmith>=0.4.10, you may selectively enable caching for requests to individual URLs or hostnames like this:
pytest features
@pytest.mark.langsmith is designed to stay out of your way and works well with familiar pytest features.
Parametrize with pytest.mark.parametrize
You can use the parametrize decorator as before. This will create a new test case for each parametrized instance of the test.
evaluate() instead. This parallelizes the evaluation and makes it easier to control individual experiments and the corresponding dataset.
Parallelize with pytest-xdist
You can use pytest-xdist as you normally would to parallelize test execution:
Async tests with pytest-asyncio
@pytest.mark.langsmith works with sync or async tests, so you can run async tests exactly as before.
Watch mode with pytest-watch
Use watch mode to quickly iterate on your tests. We highly recommend ony using this with test caching (see below) enabled to avoid unnecessary LLM calls:
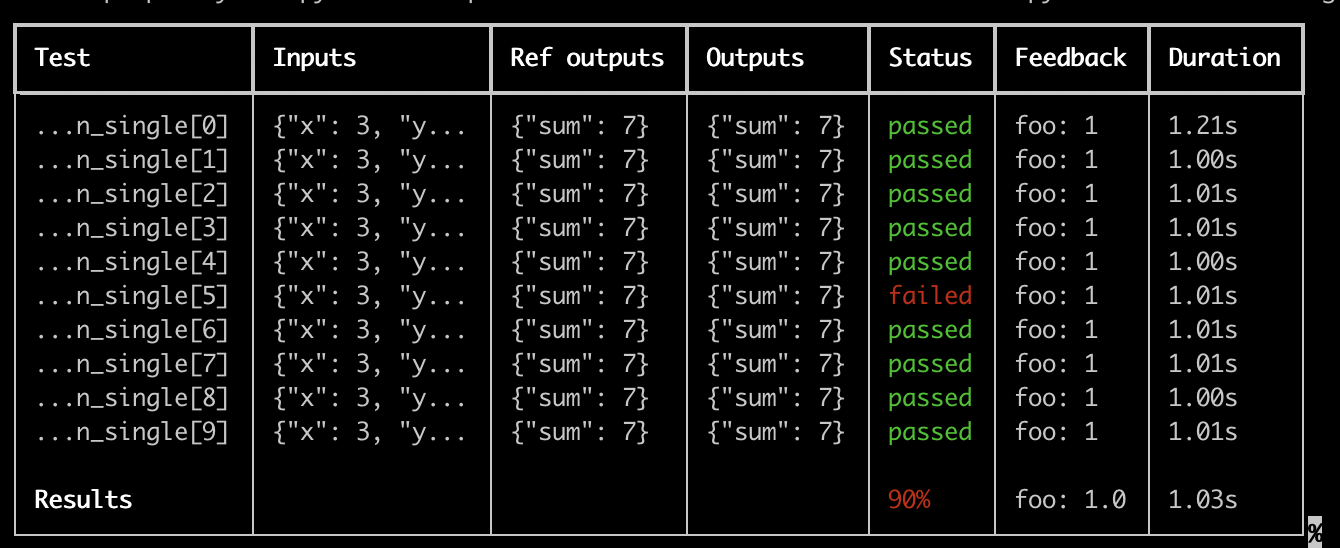
Rich outputs
If you’d like to see a rich display of the LangSmith results of your test run you can specify--langsmith-output:
--output=langsmith in langsmith<=0.3.3 but was updated to avoid collisions with other pytest plugins.
You’ll get a nice table per test suite that updates live as the results are uploaded to LangSmith:
- Make sure you’ve installed
pip install -U "langsmith[pytest]" - Rich outputs do not currently work with
pytest-xdist
Dry-run mode
If you want to run the tests without syncing the results to LangSmith, you can setLANGSMITH_TEST_TRACKING=false in your environment.
Expectations
LangSmith provides an expect utility to help define expectations about your LLM output. For example:asserting that the expectation is met possibly triggering a test failure.
expect also provides “fuzzy match” methods. For example:
- The
embedding_distancebetween the prediction and the expectation - The binary
expectationscore (1 if cosine distance is less than 0.5, 0 if not) - The
edit_distancebetween the prediction and the expectation - The overall test pass/fail score (binary)
expect utility is modeled off of Jest’s expect API, with some off-the-shelf functionality to make it easier to grade your LLMs.
Legacy
@test / @unit decorator
The legacy method for marking test cases is using the @test or @unit decorators:
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.